Llamamos a esta entrada "ayudantes de datos" porque comprende un conjunto de procedimientos de apoyo que permiten al usuario variar el orden de las variables o casos en la vista del editor de datos, reorganizar la forma en que los registros están estructurados y gestionar la contribución de cada caso a los resultados del análisis. Hay más procedimientos que se ajustan a esta categoría de "ayudantes de datos"; hemos elegido algunos exclusivamente con fines ilustrativos.
Ordenar casos y/o variables
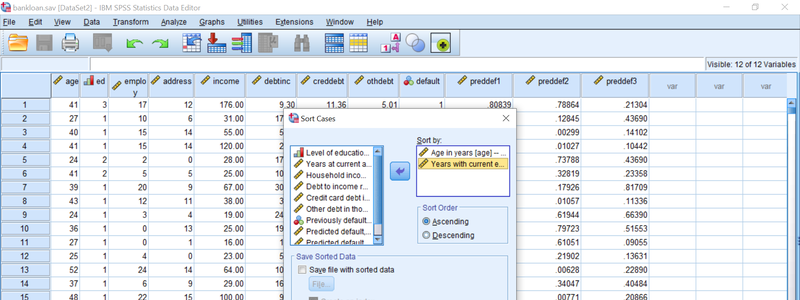
En la opción de menú principal Datos, encontramos dos procedimientos: Datos> Ordenar casos y Datos> Ordenar variables cuyos resultados son bastante obvios. Ordenar casos permite al usuario definir el orden de los casos (filas) en el Editor de datos según los valores de una o más variables (columnas). Funciona jerárquicamente, la primera variable elegida dicta el primer creiterio de ordenación (por ejemplo edad en orden ascendente) y dentro de cada grupo de valores de primera variable (individuos de 1 año de edad, luego de 2 años ...) los casos se sub-ordenan según la segunda variable elegida (altura, por ejemplo) y así sucesivamente si hubiera más criterios. Vale la pena mencionar que la clasificación basada en caracteres alfanuméricos depende del orden definido por la configuración en la que se basa en el idioma de la configuración regional, pudiendo causar resultados inesperados.
Como muestra la siguiente imagen, el procedimiento de Ordenar Casos permite la creación de un índice que refleja el orden y también guarda el archivo ordenado como un conjunto de datos independiente.
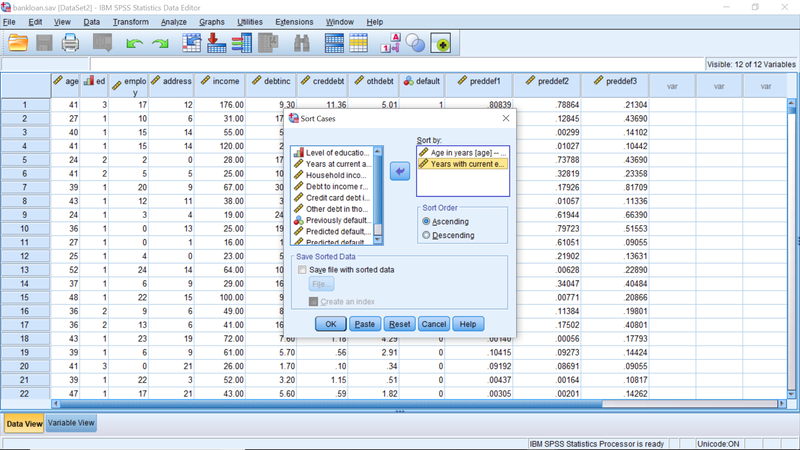
Datos> Ordenar variables varía el orden de las columnas en la vista Datos. Hay varios criterios disponibles: nombres de variables, nivel de medida, función de las variables, etc. según la imagen a continuación
Reestructurar datos
La forma en que el motor analítico procesa los datos requiere que los estos se organicen en una disposición específica: una matriz bidimensional (la disposición "física") donde cada fila representa un caso, siendo los casos independientes, y cada columna representa un campo o variable. De esta manera, esa matriz vincula el significado de los datos con su disposición. A veces este no es el caso. La reestructuración de datos es el proceso que restablece la disposición de los datos para dar significado a los resultados del análisis.
Considerando primero el caso más simple, puede suceder que las filas del conjunto de datos sean las variables y las columnas los casos. Para que esa disposición sea adecuada para el análisis, es suficiente transponer la matriz, cambiando las filas por las columnas. Eso es exactamente lo que obtenemos de Datos> Transponer, que nos permite elegir una variable para usar como nombre de las variables una vez transpuestas.
A veces sucede que el diseño experimental condiciona el significado de los datos: supongamos que estamos tomando medidas repetidas de la presión arterial a diferentes horas del día para un conjunto dado de individuos, y estamos registrando estos datos en 3 columnas: las dos primeras para la presión arterial en sí y la tercera el tiempo según (hora) según la imagen a continuación.
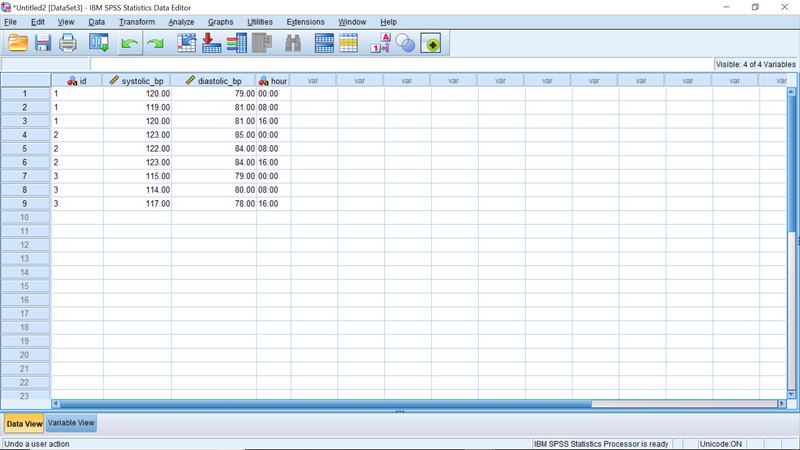
Si queremos evaluar la presencia de diferencias significativas en la presión arterial sistólica media entre horas, debemos observar la variación de la presión arterial. Según la disposición de datos anterior, la varianza de la columna systolic_bp no tendrá en cuenta el hecho de que algunas filas provienen del mismo individuo (1, 2 ...) y al calcular esta varianza de la columna estaríamos midiendo conjuntamente las variaciones "dentro" y " “entre” individuos. Es obvio que eliminar la variación dentro de los individuos hará que nuestras estimaciones del efecto horario sobre la presión arterial sean más precisas. Para ese fin necesitamos una disposición diferente de los datos como la siguiente:
Bajo esta disposición de datos, podemos ejecutar una prueba T de muestras apareadas para buscar diferencias en la presión arterial sistólica media entre, por ejemplo, 00:00 horas y 08:00 h.
El paso de la primera a la segunda disposición de datos se realizó a través de Datos> Reestructurar, seleccione Casos en Variables, haga clic en siguiente, coloque "id" como variable de identificación y "hora" como variable de índice y luego haga clic hasta que se complete el procedimiento.
Revertir esta disposición a la original se puede lograr a través del procedimiento de reestructuración de datos "Variables en casos". Le sugerimos que lo intente.
Una observación final: estas transformaciones de reestructuración pueden ser un poco más complejas que las ilustradas aquí, ya que requieren tener en cuenta la estructura de datos apropiada para el procedimiento analítico particular a aplicar.
Ponderando casos
Nuestro procesador analítico otorga por defecto el mismo peso a cada caso (fila) que considera en el análisis. Si hay n filas con información no faltante para una variable en particular, sea por ejemplo la presión arterial sistólica, cada fila o caso "pesará" 1 / n al calcular la media. Algoritmos más complejos que combinen más variables como los procedimientos de regresión funcionarían de la misma manera, siempre que todas las variables que ingresen en las ecuaciones tengan información completa (existen varias estrategias para manejar los valores faltantes para cada algoritmo en particular, pero esta no es la cuestión a tratar aquí) .
A veces, las filas no representan instancias equivalentes en términos de análisis y queremos usar pesos específicos para cada caso o grupo de casos. Eso es "ponderar". Por ejemplo, cuando los casos provienen de un muestreo no aleatorio sino de diseños de muestreo más complejos, o simplemente cuando queremos corregir la frecuencia muestral de los mismos casos para que coincida mejor con la frecuencia poblacional conocida.
El procedimiento Datos> Ponderar Casos hace el trabajo. Después de elegir la variable de ponderación adecuada, verá en la esquina inferior derecha del editor de datos que el procesador entra en el estado “ponderado", es decir, hasta revocar el comando ejecutado, cualquier análisis se realizará con esas ponderaciones particulares.
