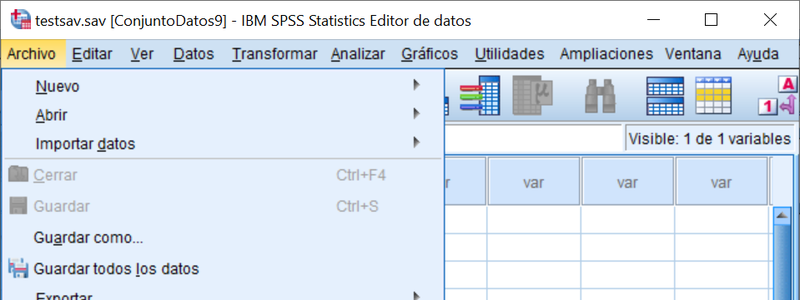
A continuación, repasamos las opciones principales del Menú del Editor de Datos comenzando por la primera: Archivo, que se despliegan en la siguiente imagen:
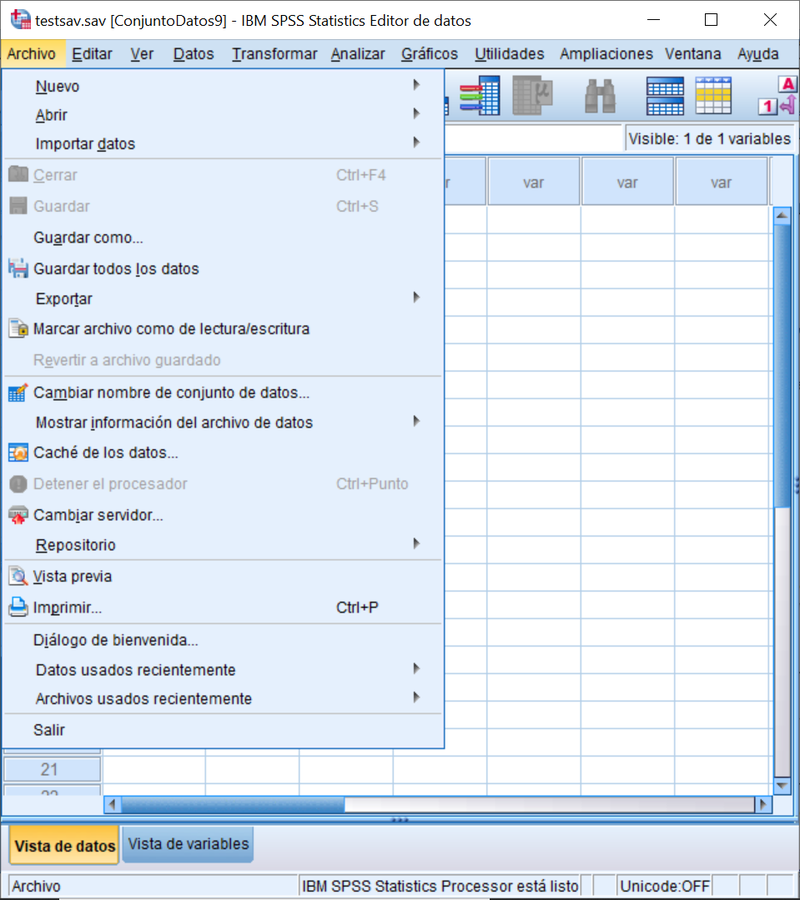
Nuevo: permite abrir un nuevo archivo que puede ser de Datos (un conjunto de datos vacío), de Sintaxis nativa de IBM SPSS Statistics (el editor de comandos), de Resultados (el editor donde se colocan por defecto los resultados del análisis), o el editores de Sintaxis del lenguaje Basic o Python.
Abrir: presenta las mismas opciones que la opción anterior (nuevo) pero para abrir archivos previamente existentes. Es importante saber que IBM SPSS Statistics puede tener más de un conjunto de datos “abierto” simultáneamente, pero solo uno de ellos estará activo en un momento dado y será sobre este conjunto que se ejecuten las operaciones. Para hacerlo de forma rápida con fines ilustrativos vaya a la opción Archivo>Diálogo de bienvenida como muestra la imagen siguiente:
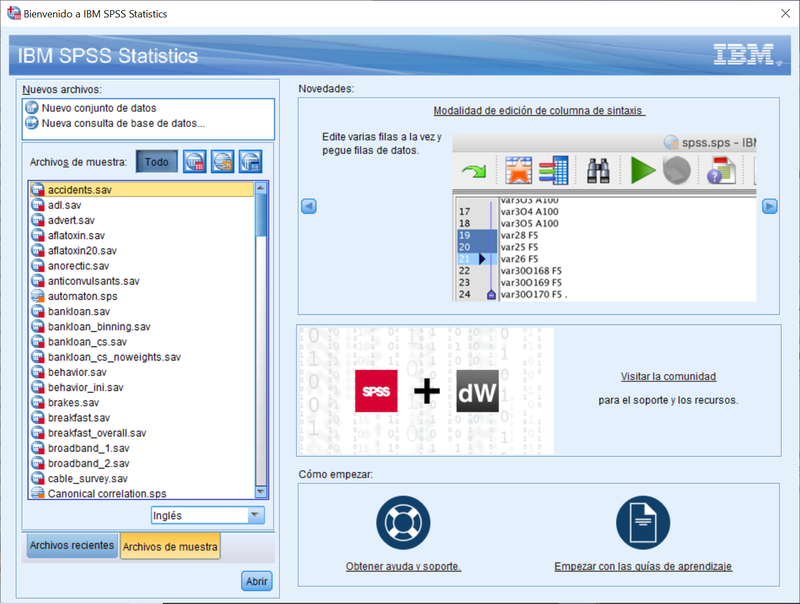
Haga click en la pestaña “archivos de muestra” en la parte inferior izquierda de la pantalla y abra varios de los archivos aquí relacionados. Por defecto, el conjunto de datos activo será el último que haya abierto. Si cambia de conjunto de datos activo vaya al menú: Ventana> y elija el conjunto de datos deseado.
Importar datos: es la operación de traer a IBM SPSS Statistics datos que están guardados en formatos diferentes. Bases de datos (permitiendo la creación/edición/ejecución de consultas), libros Excel, CSV, texto y diversos formatos de otros sistemas propietarios. Usualmente cada opción escogida lleva al usuario de la mano de un asistente que le va guiando a través de pasos sucesivos.
Cerrar: cierra la ventana activa (de sintaxis, resultados o datos) es importante señalar que en el caso del editor de datos debe de haber más de una ventana de datos abierta para que esta opción esté disponible, pues con una solamente supondría el abandono de la sesión.
Guardar y Guardar como: son para guardar las ventanas activas del visor (sean datos, sintaxis o resultados). Para el caso de datos, Guardar como es mas flexible permitiendo elegir diferentes formatos y decidir que variables se guardan y cuáles no.
Guardar todos los datos: guarda todos los datos de un determinado conjunto de datos activo sobre el que estemos trabajando.
Revertir a archivo guardado: quien trabaje con ficheros electrónicos es muy consciente de la importancia que tiene disponer de versiones consolidadas del documento de trabajo con el que se interactúa. Los archivos de datos no son la excepción. Los análisis exploratorios suponen la creación de nuevas variables y/o casos así como la desaparición de variables y/o casos existentes. A veces es necesario volver rápidamente a la última versión guardada. Esto es lo que permite esta opción.
Exportar: es la operación inversa a importar. Si llegado aquí tiene alguna duda, le recomendamos que revise las operaciones de importación de datos.
Marcar archivo como de lectura/escritura: Estamos trabajando sobre un Conjunto de Datos activo que abrimos a partir de un archivo determinado en disco. Hacemos múltiples operaciones alterando casos y variables. Sin pensarlo mucho hacemos Archivo>Guardar y sobrescribimos el fichero original de forma que perdemos la información tal cual estaba. Si quiere prevenir esta pequeña “calamidad” que nos hace perder tiempo y ganas, proteja el archivo en disco marcándolo como de “lectura”: impedirá que se sobrescriba el fichero. Esto es especialmente útil al salir de la sesión (última de las opciones que veremos) porque podemos fácilmente permitir una sobreescritura indeseada. Marcar como “escritura” deshace obviamente la operación anterior.
Cambiar nombre de Conjunto de Datos: Los distintos conjuntos de datos simultáneamente abiertos en el visor presentan un nombre distinto del archivo subyacente en disco. Normalmente se denominan” ConjuntoDatosX” donde X toma valores enteros empezando en el cero de forma secuencial atribuyéndose el número conforme al orden en que se abren esos conjuntos de datos en cada sesión activa. Este identificador se ve en la parte superior de la pantalla. Pues bien, es posible cambiar este nombre que es atribuido por defecto, a través de esta opción. Es especialmente recomendable cuando se trabaja a través de sintaxis en vez de interactivamente pues, habiendo múltiples conjuntos de datos abiertos, las operaciones se realizaran sólo sobre un conjunto en particular: el activo. Para ello es necesario activar el conjunto que se desee y es mas sencillo hacerlo a través de un nombre distintivo y fácil de interpretar, como por ejemplo “Datos de test”, en vez de “ConjuntoDatos33”.
Mostrar información del archivo de datos: saber en todo momento los contenidos de los conjuntos de datos (activos o archivados) es imposible. Y entiéndase por contenidos tanto los datos en sí como los metadatos, es decir, las etiquetas de las variables, sus escalas de medida, etiquetas de valor, tipo de archivo, codificación…. Esto se hace posible mediante esta opción de menú. Pruebe a preguntar la información de algún conjunto activo o archivo guardado por IBM SPSS Statistics y no olvide ir a consultar los resultados al visor de resultados activo mediante el menú: Ventana y elegir la deseada.
Caché de datos: consiste en cargar los datos de un archivo de forma que sean mas rápidamente accesibles en operaciones posteriores. Aumenta la velocidad de muchas operaciones pero, en las ocasiones en que se trata de conjuntos de datos de gran tamaño, puede consumir recursos de cómputo significativos.
Detener el procesador: el estado del procesador se informa en la parte inferior de la pantalla. En el gráfico anterior podemos leer ”IBM Statistics Processor está listo” queriendo decir que está dispuesto para recibir y ejecutar órdenes. A veces la ejecución puede tomar mucho tiempo y deseamos interrumpirla antes de que acabe. Es exactamente tal interrupción la que se realiza a través de esta opción.
Cambiar servidor: Disponible solo cuando se trabaja en modo cliente-servidor, permite la elección del servidor que ejecutará los comandos debidamente credenciado.
Repositorio: Es una opción avanzada. Requiere disponer de la plataforma de IBM SPSS Collaboration and Deployment Services que permite administrar y distribuir los activos de los análisis predictivos: control de versiones, entornos de producción y desarrollo, multiusuario, automatización de tareas, etc.
Vista previa: ofrece una “imagen” de los datos que hay en el editor, especialmente útil antes de la opción de menú siguiente.
Imprimir: con funcionalidades evidentes
Diálogo de bienvenida: contiene algunas indicaciones sobre las novedades, cómo obtener ayuda, conectar con la comunidad de usuarios y, como hemos visto con anterioridad, un acceso cómodo a los ficheros con datos de ejemplo.
Datos usados recientemente / Archivos usados recientemente: como es usual en las interfaces de usuarios son atajos para acceder a archivos o conjuntos de datos de uso reciente.
Salir: abandonar la sesión con las consiguientes preguntas relativas a guardar o no los trabajos en curso antes de hacerlo. Mucho cuidado con sobrescribir ficheros indeseados.
