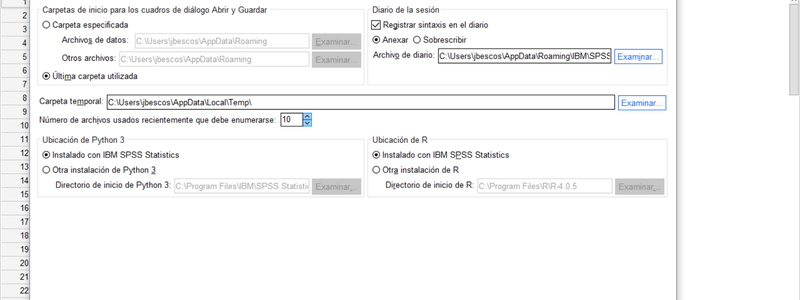
La versión 28 de IBM SPSS Statistics instala su propio entorno de ejecución de R, pero si vd. ya dispone de una instalación de R en la que desee trabajar, puede especificarla en la pestaña "Ubicación de Archivos" del menú EDITAR>OPCIONES. Dicho entorno de R -instalado por defecto con esta versión- es accesible de forma independiente a través de "R for SPSS Statistics (GUI)" en la carpeta "IBM SPSS Statistics" del menú principal de programas (bajo Windows).
Siempre será conveniente familiarizarse con tal entorno, así que entremos en el mismo y tecleemos, como ilustra la imagen a continuación : install.packages("tidyverse") pulsando la tecla "enter" para finalizar. Tidyverse consiste en un conjunto de librerías que permiten programar de forma clara e inteligible una serie de acciones sobre datos que enseguida ilustraremos. Una vez instaladas las librerías Tidyverse, podemos salir da la interface de R para lo cual basta teclear q() o quit() y pulsar "enter" (responder "no" a la pregunta sobre guardar el área de trabajo) . Las librerías Tidyverse han quedado instaladas y sólo será necesario invocarlas cuando se desee acceder a alguna de las funciones y/o procedimientos que contienen.
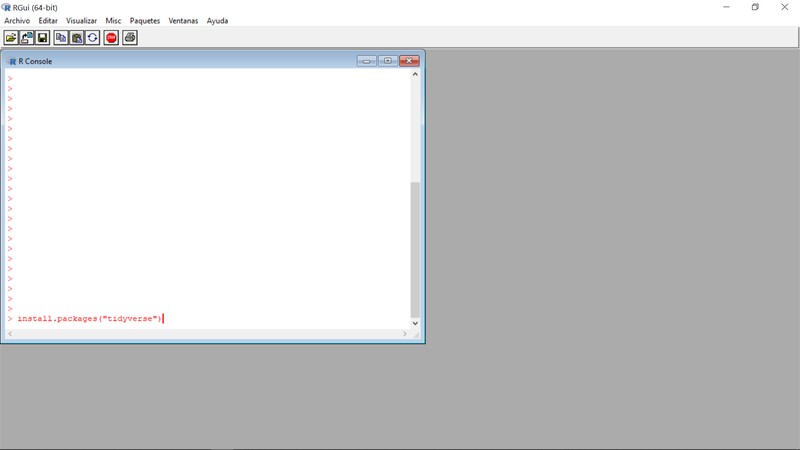
Instalando librerías en R
Ahora queremos enviar un conjunto de datos desde IBM SPSS Statistics al entorno de R en cuestión. Para mayor claridad, lo haremos desde el entorno integrado de sintáxis y resultados denominado Libro de Trabajo o Workbook, una de las novedades de la versión 28 de IBM SPSS Statistics como descrito en la entrada anterior. Es necesario habilitar los Libros de Trabajo en el epígrafe "Modo de Aplicación" de la pestaña "General" del menú EDITAR>OPCIONES de SPSS Statistics, escogiendo la opción correspondiente.
Vayamos paso a paso:
Paso 1: Abrimos el fichero de muestra "telco.sav".
Accesible desde la pantalla de bienvenida de IBM SPSS Statistics, pestaña "Archivos de muestra" como se ilustra en el gráfico siguiente:
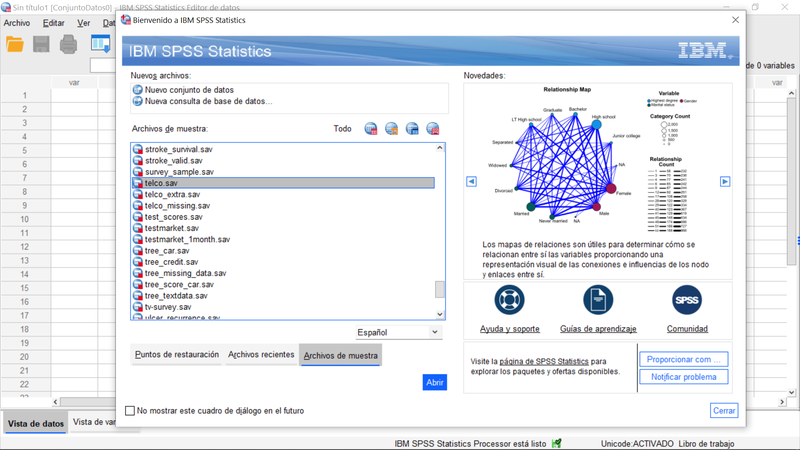
Abriendo "telco.sav"
Se trata de un conjunto de datos simulados sobre clientes de una empresa de telecomunicaciones que están convenientemente codificados como se puede comprobar en la pestaña "Vista de variables" del Editor de Datos de SPSS Statistics. Es imprescindible que, si tiene más de un conjunto de Datos abierto en SPSS, telco.sav sea el conjunto de datos activo para que este ejemplo funcione correctamente.
Paso 2: Abrimos un libro de trabajo nuevo.
Como ilustra el gráfico siguiente, la petición al entorno R para que ejecute una serie de comandos, se realiza por bloques de código que son los comprendidos entre los comandos de sintaxis:
BEGIN PROGRAM R.
{Código R, comentarios, y comandos específicos para intercambiar datos entre SPSS y R.}
END PROGRAM.
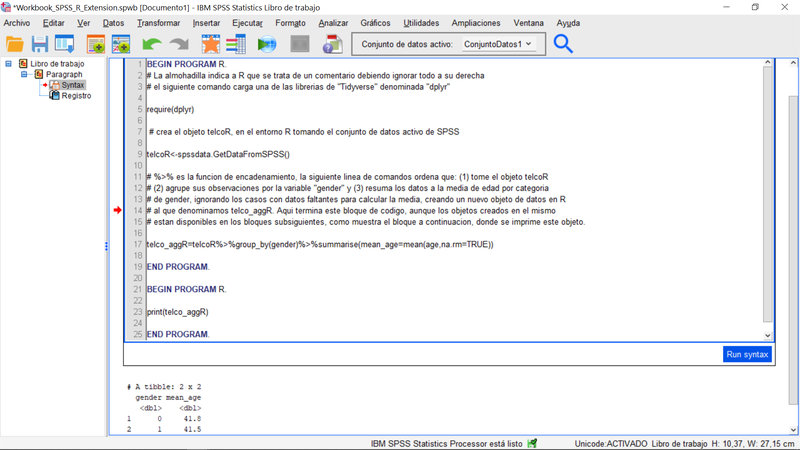
Libro de trabajo con comandos R comentados
En la imagen, las líneas precedidas por la almohadilla (#) son comentarios, pues este símbolo informa a R para que ignore todo lo que está a su derecha. Se emplean aquí para describir las operaciones. Si quiere replicar el ejemplo, basta con que copie en su propio Libro de trabajo el siguiente texto, libre de anotaciones:
BEGIN PROGRAM R. require(dplyr) telcoR<-spssdata.GetDataFromSPSS() telco_aggR=telcoR%>%group_by(gender)%>%summarise(mean_age=mean(age,na.rm=TRUE)) END PROGRAM. BEGIN PROGRAM R. print(telco_aggR) END PROGRAM.
Paso 3: Ejecutemos el código del libro de trabajo.
Click sobre el botón "Run Syntax" y obtendremos, en el propio libro, el resultado anticipado: un objeto de R de la clase tibble con las edades medias agregadas por género. Hasta aquí hemos visto cómo enviar datos a R y transformarlos. Avancemos algo más.
Paso 4: Crear un diccionaro de datos nuevo y devolverlo conjuntamente con los datos resultantes de las transformariones realizadas por R a IBM SPSS Statistics.
Para este fin es necesario emplear la notación especifica que usa IBM SPSS Statistics en su interface con R. Para detalles recomendamos buscar en la web : "SPSS Integration Plug-in for R". Las lineas de código del siguiente bloque de programación ejecutan los procedimientos descritos respectivamente un poco más abajo.
BEGIN PROGRAM R. telco_aggR<-telco_aggR%>%ungroup() genero<-c("genero", "Genero", 0, "F8", "nominal") edad_media<-c("edad_media", "Edad media", 0, "F8","scale") diccionario<-spssdictionary.CreateSPSSDictionary(genero, edad_media) spssdictionary.SetDictionaryToSPSS("resultados", diccionario) spssdata.SetDataToSPSS("resultados",telco_aggR) spssdictionary.SetActive("resultados") spssdictionary.EndDataStep() END PROGRAM.
- El objeto R telco_aggR deja de estar agrupado por género
- Se crea un vector R llamado "genero" que contiene (convención SPSS) respectivamente: el nuevo nombre de la variable, su etiqueta, el tipo de variable , el formato,y su nivel de medida.
- Igual que el anterior pero ahora el objeto se llama "edad_media". Repare que vamos a modificar los nombres de las variables que tenemos en terco_aggR, que eran "gender" y "mean_age".
- Creamos un nuevo diccionario de datos SPSS con los objetos R (vectores) definidos en los 2 pasos anteriores cuyos contenidos responden a una convención estricta.
- Instruimos a SPSS para que establezca este nuevo objeto como el diccionario de datos de un nuevo conjunto que vamos a denominar "resultados"
- Asginamos telco_aggR como los datos que van juntarse con el diccionario recién creado en el conjunto de datos "resulados"
- Establecemos el conjunto de datos "resultados" como conjunto de datos activo
- terminamos las operaciones llamando a la función apropiada.
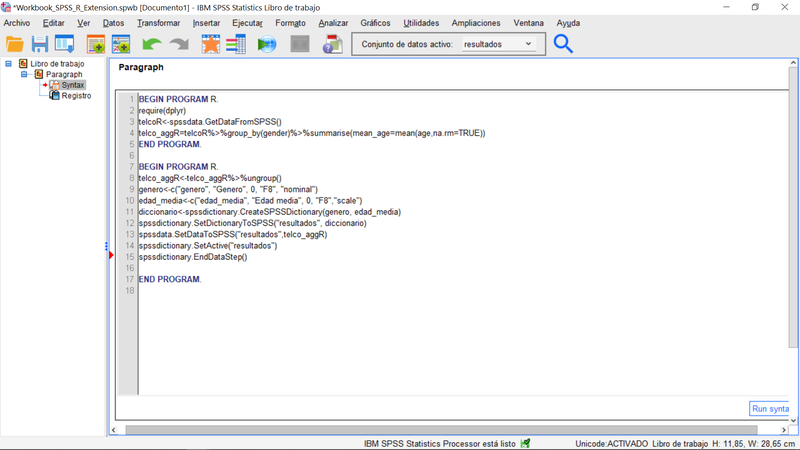
Nuevo libro de trabajo sin comentarios R.
Paso 5: Comprobando los resultados.
Si ejecutamos el código del Libro de Trabajo de la imagen anterior, regresando al entorno de IBM SPSS Statistics nos encontraremos, como no podía ser de otra forma, el nuevo conjunto de datos activo, con su correspondiente diccionario accesible en la pestaña "vista de variables" del visor de datos.
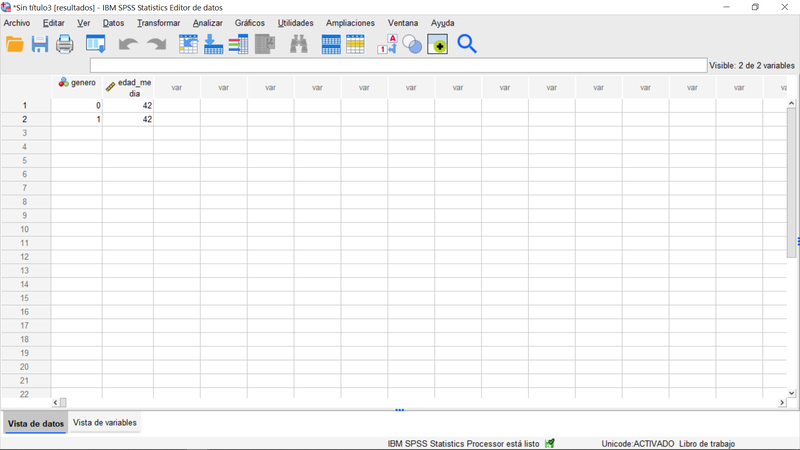
Visor de Datos, vista de datos
