Podemos decir que el tema principal del lanzamiento fue el cálculo de los intervalos de confianza, una funcionalidad muy popular para presentar resultados estadísticos entre la comunidad profesional. Proporciones y correlaciones se han agregado a la lista de estadísticas para las cuales en SPSS puede calcular el intervalo de confianza por diferentes métodos con solo un par de clics.
Procedimientos estadísticos
Pruebas de hipótesis e intervalos de confianza para proporciones
La nueva versión de SPSS agrega procedimientos para evaluar y comparar proporciones en las siguientes situaciones:
- Estimación de la proporción en una muestra
- Proporciones en muestras independientes
- Proporciones en muestras apareadas
Se incluyen nuevos procedimientos en la sección de comparación de promedios (las proporciones pueden entenderse como un caso particular de promedios).
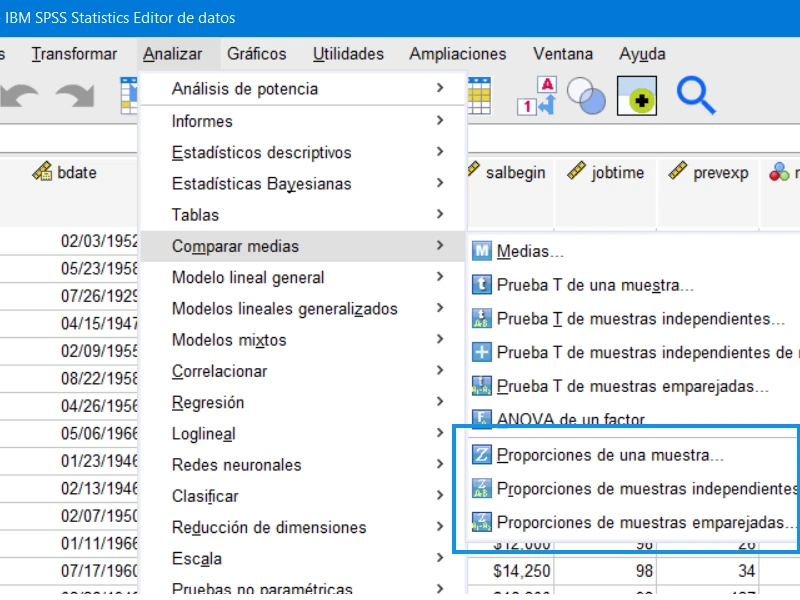
Los 3 nuevos procedimientos permiten seleccionar variables que especifican las proporciones, el nivel de cobertura del intervalo de confianza y los métodos para su cálculo (hay muchas opciones disponibles y su variedad se debe a la representación de diferentes métodos en la literatura profesional). Las variables de proporción pueden ser categóricas o numéricas: simplemente especifique una regla para resaltar la proporción objetivo de interés (la categoría denominada "éxito"). Puede ser un valor específico o un umbral por encima del cual todo se clasifica como "correcto", o el mínimo / máximo de los valores disponibles.
Disponible para escenarios específicos de estimación:
- para estimar la proporción de una muestra - el valor verificado de la proporción
- para estimar las proporciones de muestras independientes: una variable de agrupación y una regla para seleccionar grupos
- Para estimar las proporciones de muestras apareadas.
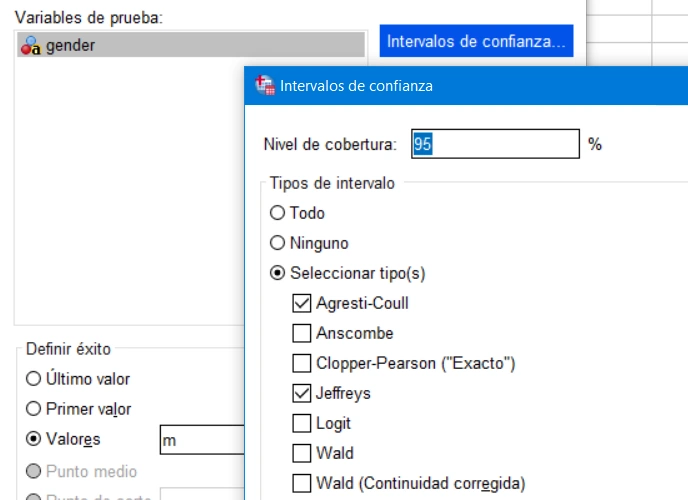
Selección de intervalos de confianza para estimar la proporción de una muestra en el cuadro de diálogo IBM SPSS Statistics 27.0.1
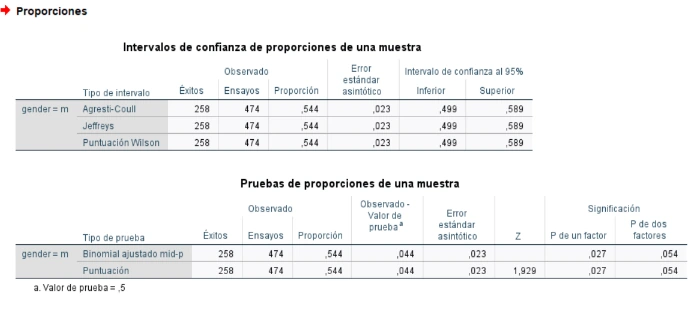
Intervalos de confianza y resultados del contraste sobre proporciones (una muestra) en IBM SPSS Statistics 27.0.1
En el procedimiento para una muestra, el intervalo de confianza corresponde a la proporción medida directamente, y en los procedimientos para muestras independientes y apareadas, a la diferencia entre las proporciones comparadas.
Intervalos de confianza para coeficientes de correlación
En el procedimiento para estimar correlaciones por pares para todos los tipos de coeficientes (Pearson, Spearman, tau-b de Kendall), está ahora disponible el cálculo de intervalos de confianza. El fácil acceso al trazado de los intervalos de confianza para las correlaciones es otro paso hacia el cumplimiento de los requisitos de publicación de estadísticas actuales. Los intervalos de confianza se muestran en una tabla separada, donde cada fila está formada por un par de variables. La información sobre el valor del coeficiente de correlación y su significación estadística en la matriz de correlaciones se repite en esta nueva tabla.
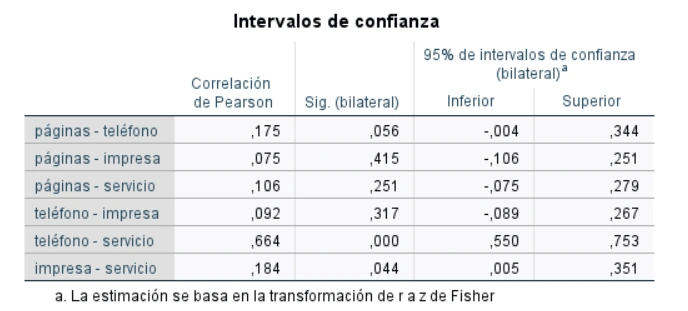
Tabla con los intervalos de confianza para los coeficientes de correlación en IBM SPSS Statistics 27.0.1
Si lo desea, puede suprimir la salida de la matriz utilizando la palabra clave NOMATRIX en la sintaxis. Igualmente, puede personalizar el nivel de confianza del intervalo deseado. Además, el usuario puede optar por aplicar la corrección al realizar la transformación de Fisher para el coeficiente de correlación y elegir una de las tres opciones para estimar la desviación estándar para el coeficiente de correlación de Spearman.
Nuevo modelo Omega de McDonald's en análisis de fiabilidad
El Omega es una alternativa relativamente nueva a la métrica alfa de Cronbach tradicional, que mide la consistencia de las escalas. Por ejemplo, si queremos medir el nivel de competencia en un idioma extranjero, los elementos de la escala pueden ser evaluaciones de las habilidades para escuchar, hablar, leer y escribir. El análisis de fiabilidad debe responder a la pregunta de si la escala en su conjunto realmente mide un valor único (alguna propiedad común), o si las métricas individuales se eliminan del coro general. El alfa de Cronbach es un modelo de medición reconocido que se puede encontrar en miles de publicaciones científicas, pero no está exento de inconvenientes. Por lo tanto, debido a que los supuestos subyacentes a su cálculo se verifican rara vez en la práctica , la evaluación de la fiabilidad de alfa a menudo será una infraestimación. El coeficiente Omega no supone asunciones tan restrictivas y será frecuentemente la medida de fiabilidad preferida. La interpretación de su valor es la misma que la del alfa: en una escala consistente, esperamos ver omega, al menos en el intervalo de valores desde 0,7 a 0,8.
Nuevo parámetro en procedimiento para imputación de datos múltiples
El procedimiento de imputación múltiple está diseñado para restaurar las lagunas en los datos con el fin de guardar tantas observaciones completas como sea posible en el análisis o para estudiar patrones típicos de ocurrencia de valores perdidos. En el correspondiente comando de IMPUTACIÓN MÚLTIPLE Predictive Mean Matching, se ha agregado como parámetro el número de observaciones completas más cercanas al candidato predicho a considerar en la imputación. La cuestión aquí es que en los casos en que se utiliza un modelo (por ejemplo, regresión lineal) para imputar datos, el valor predicho para reemplazar el faltante puede ser inverosímilmente grande o pequeño. En el enfoque Predictive Mean Matching, el valor predicho se establece en función de los valores reales más cercanos de los datos al pronóstico, y el nuevo parámetro controla el número de esos casos más cercanos a considerar.
Autocompletar nombres de variables en el editor de sintaxis
Los usuarios que utilizan el lenguaje de comandos (sintaxis) de SPSS están acostumbrados al hecho de que los nombres de los procedimientos, subcomandos y palabras clave están codificados por colores en el editor de sintaxis, y que al introducir comandos desde el teclado, el editor ofrezca opciones de finalización (autocompletado).
La versión 27.0.1 también agrega el autocompletado de los nombres de variables del conjunto de datos activo, lo que acelera enormemente el desarrollo de la sintaxis: ya no es necesario recordar nombres largos de variables de memoria, usar copiar / pegar o usar el cuadro de diálogo Variables para insertar variables en la sintaxis. Simplemente comience a escribir las primeras letras del nombre de la variable que desea y elija la opción de finalización entre las opciones que se abren ante usted.
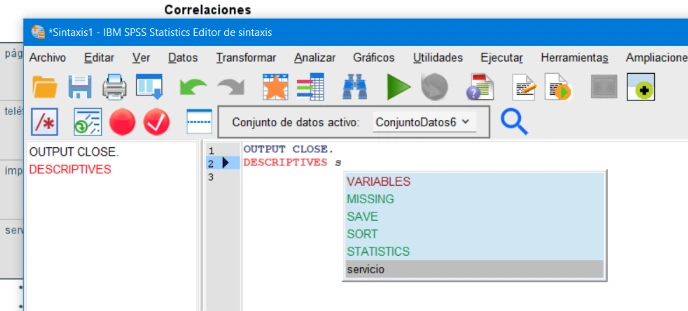
Autocompletar al ingresar nombres de variables en el editor de sintaxis de IBM SPSS Statistics 27.0.1
Puntos de recuperación
Una extensión de la función de guardado automático introducida en el lanzamiento de IBM SPSS Statistics 27 agrega la capacidad de crear puntos de restauración personalizados. Un punto de restauración es en realidad una instantánea de todos los archivos abiertos actualmente en SPSS Statistics, que se crea sin guardar explícitamente estos archivos por separado. Al crear un punto de restauración, el usuario le pide a SPSS que "recuerde" el estado actual para que pueda volver rápidamente a él más tarde. Después de eso, los datos, la sintaxis y la salida se pueden cambiar según se desee (por ejemplo, se realizó algún tipo de análisis auxiliar, cuyos resultados no necesitan guardarse). Después de seleccionar el punto guardado, el usuario volverá a ver el estado "memorizado" de los archivos.
Control de salida
Exportación de gráficos agregados a formato vectorial .svg
Se ha agregado una opción para exportar gráficos a formato vectorial .svg. Los renders guardados de esta manera se pueden escalar sin pérdida de calidad. Además, los formatos de archivos vectoriales son generalmente de menor tamaño que los formatos de mapa de bits tradicionales como .jpeg o .png.
Botones agregados para un formateo más rápido
Con los nuevos botones para disminuir y aumentar la cantidad de decimales mostrados, puede personalizar rápidamente la apariencia de la tabla con la precisión deseada de presentación de datos.
Si necesita revertir rápidamente la configuración para la apariencia de una tabla o gráfico al original, puede usar el nuevo botón de reinicio.
Configuración de diseño de tabla ampliada
Opciones agregadas a la configuración del programa:
- deshabilitar la salida de notas y notas al pie de las tablas;
- reemplazo pequeños valores de significación estadística (valor p) por "<0,001". Anteriormente, si el nivel de significancia de la prueba estadística era menor que 0,0005, la tabla mostraba los primeros 3 lugares decimales por defecto, es decir, ceros. Puede ver el valor exacto haciendo clic en una celda en el modo de edición de tabla. Esta posibilidad se conserva con la nueva configuración de formato.
Con la ayuda de Predictive Solutions, puede convertirse en usuario de la nueva versión de IBM SPSS Statistics y, lo más importante, recibir un soporte técnico competente. Si tiene alguna pregunta, escríbanos a: info@predictivesolutions.es.
